
以前、「完全オフライン環境で動作する生成AIモデルの日英翻訳能力比較レポート」という記事を書きましたが、情報漏洩リスクのあるクラウド系生成AIを避け、ローカルLLMの利用を考える企業や人が増えているようです。
そこで問題になってくるのは、自分のPCにローカルLLMを導入する場合、どのモデルなら快適な速度で動くのかという点ですよね。それを教えてくれるサイトがありました。以下URLの「Can I Run AI Locally?」というサイトです。
ローカルLLMを導入する予定のPCでこのサイトにアクセスすると、使用しているPCのCPU, GPU, Memoryを検出して、さまざまなモデルを動かした場合の快適度を表示してくれます。
次のスクショは、私のPCをチェックした結果です。
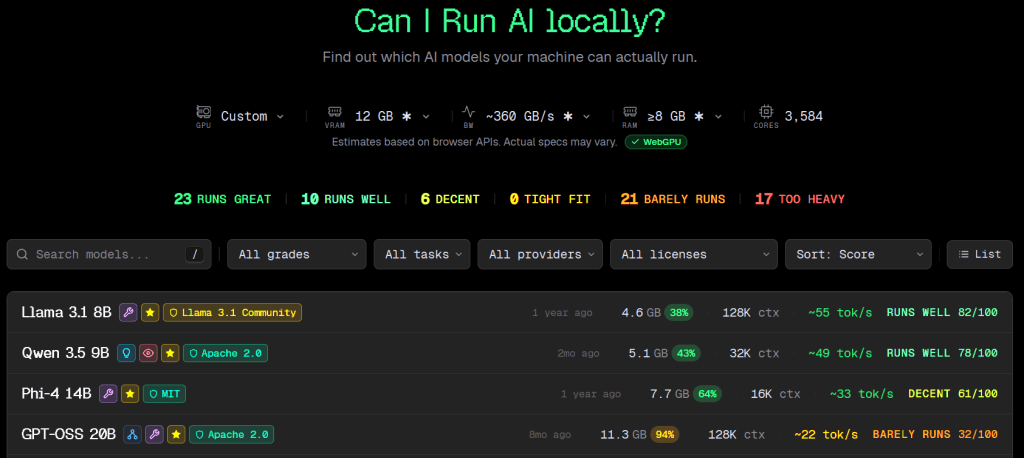
右に表示される「RUNS WELL」や「DECENT」が動作の快適度ですが、私の体感と合っています。ライセンス種類も表示してくれるので、商用利用される場合は参考になるでしょう。
流石に私のPCのスペックが低いので、パラメータサイズ14B辺りまでが精一杯のようです。ちなみに私が持つMacbook Air (M1, 8GB)で確認したら、4B辺りで「DECENT」でした。
以上、ローカルLLMを選択する際の参考にしてみてください。

